A unified notation for sharding
We use a variant of named-axis notation to describe how the tensor is sharded in blocks across the devices: we assume the existence of a 2D or 3D grid of devices called the device mesh where each axis has been given mesh axis names e.g. X, Y, and Z. We can then specify how the matrix data is laid out across the device mesh by describing how each named dimension of the array is partitioned across the physical mesh axes. We call this assignment a sharding.
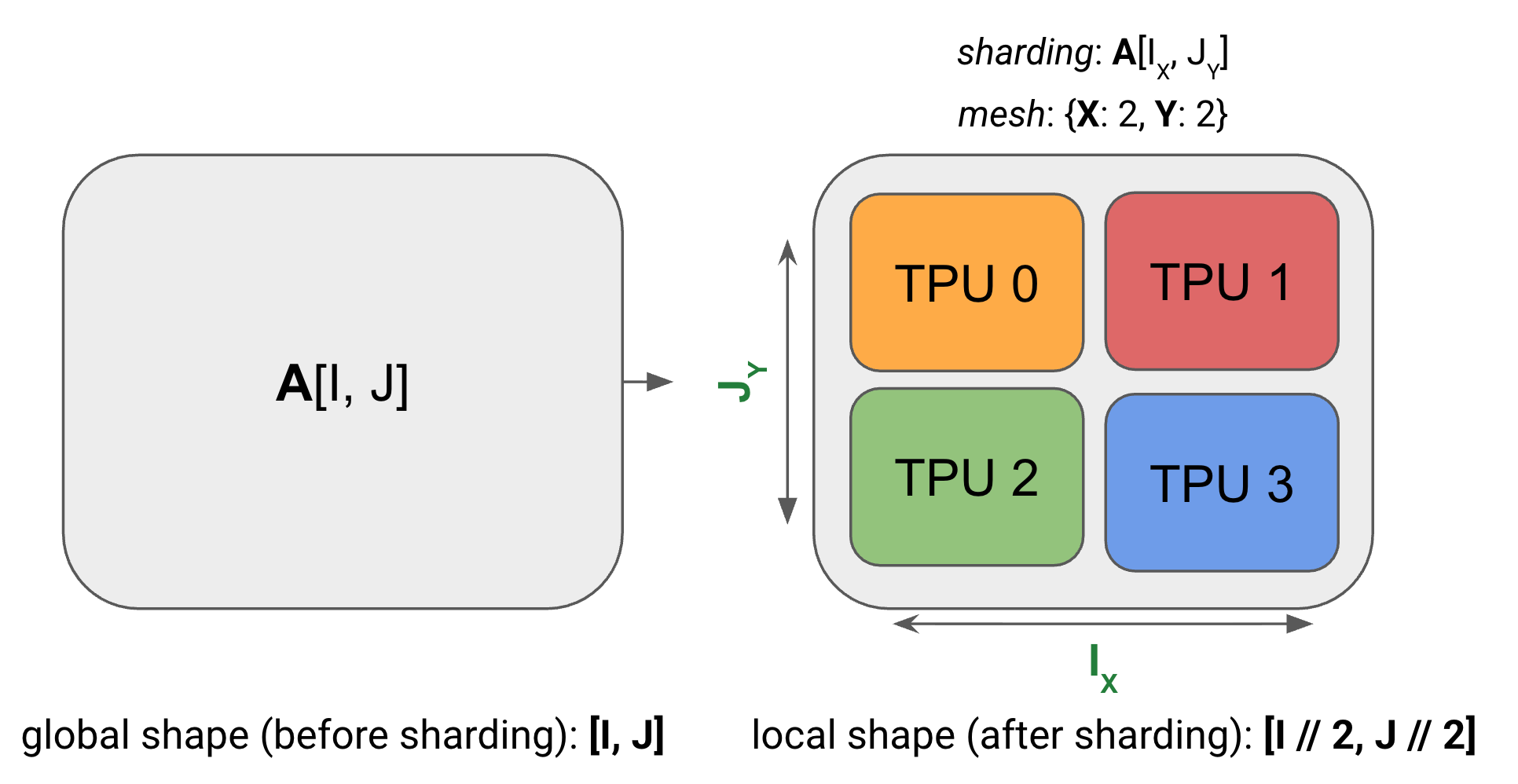
Example (the diagram above): For the above diagram, we have:
- Mesh: the device mesh above
Mesh(devices=((0, 1), (2, 3)), axis_names=(‘X', ‘Y')), which tells us we have 4 TPUs in a 2x2 grid, with axis names X and Y . - Sharding: , which tells us to shard the first axis, , along the mesh axis , and the second axis, , along the mesh axis . This sharding tells us that each shard holds of the array.
Lastly, note that we cannot have multiple named axes sharded along the same mesh dimension. e.g. is a nonsensical, forbidden sharding. Once a mesh dimension has been used to shard one dimension of an array, it is in a sense “spent”.
Computation with sharded arrays
Case 1: neither multiplicand has a sharded contracting dimension
Lemma: when multiplying sharded matrices, the computation is valid and the output follows the sharding of the inputs unless the contracting dimension is sharded or both matrices are sharded along the same axis.
For example, this works fine \begin{equation*} \mathbf{A}[I_X, J] \cdot \mathbf{B}[J, K_Y] \rightarrow \mathbf{C}[I_X, K_Y] \end{equation*} with no communication whatsoever, and results in a tensor sharded across both the X and Y hardware dimensions.
Case 2: one multiplicand has a sharded contracting dimension
Let’s consider what to do when one input A is sharded along the contracting J dimension and B is fully replicated:
We cannot simply multiply the local chunks of A and B because we need to sum over the full contracting dimension of A, which is split across the X axis. Typically, we first “AllGather” the shards of A so every device has a full copy, and only then multiply against B:
- When multiply matrices where one of the matrices is sharded along the contracting dimension, we generally AllGather it first so the contraction is no longer sharded, then do a local matmul.
Case 3: both multiplicands have sharded contracting dimensions
The third fundamental case is when both multiplicands are sharded on their contracting dimensions, along the same mesh axis:
-
In this case the local sharded block matrix multiplies are at least possible to perform, since they will share the same sets of contracting indices.
-
But each product will only represent a partial sum of the full desired product i.e. partial sum of outer products.
- A matmul can be defined as a sum of rank-1 outer products
-
This is so common that we extend our notation to explicitly mark this condition:
-
The notation reads “unreduced along X mesh axis” and refers to this status of the operation being “incomplete” in a sense, in that it will only be finished pending a final sum.
-
We can perform this summation using a full AllReduce across the X axis to remedy this: \begin{align*} A[I, J_X] \cdot_\text{LOCAL} B[J_X, K] \rightarrow &\ C[I, K] \{ U_X \} \\ \textbf{AllReduce}_X C[I, K] \{ U_X \} \rightarrow &\ C[I, K] \end{align*}
-
AllReduce removes partial sums, resulting in each device along the axis having the same fully-summed value.
Case 4: both multiplicands have a non-contracting dimension sharded along the same axis
Each mesh dimension can appear at most once when sharding a tensor. Performing the above rules can sometimes lead to a situation where this rule is violated, such as:
This is invalid because a given shard, say i, along dimension X, would have the (i, i)th shard of C, that is, a diagonal entry. There is not enough information among all shards, then, to recover anything but the diagonal entries of the result, so we cannot allow this sharding.
The way to resolve this either to A or B.
Communication Primitives
AllGather
- An AllGather removes the sharding along an axis and reassembles the shards spread across devices onto each device along that axis.
- Using the notation above, an AllGather removes a subscript from a set of axes, e.g.
How is it performed?
- To perform a 1-dimensional AllGather around a single GPU axis (a ring), we basically have each GPU pass its shard around a ring until every device has a copy.
- We can either do an AllGather in one direction or both directions
- If we do one direction, each TPU sends chunks of size over hops around the ring. If we do two directions, we send 2 chunks of size over hops.
Runtime
-
Let’s take the bidirectional AllGather and calculate how long it takes.
-
Let be the number of bytes in the array, and be the number of shards on the contracting dimension.
-
Then from the above diagram, each hop sends bytes in each direction, so each hop takes
-
Here, we assume that the GPU sends one chunk and receives one, thus 2 chunks are sent through the bidirectional link. is the bidirectional ICI bandwidth.
-
A given GPU will need to send a total of hops so that its own shard reaches the other end of the ring
-
Thus, the total reduction takes
-
This doesn’t depend on the sharding !
- The exact sharding doesn’t matter, the bottleneck is the speed of the slowest link
-
TAKEAWAY: when performing an AllGather (or a ReduceScatter or AllReduce) in a throughput-bound regime, the actual communication time depends only on the size of the array and the available bandwidth, not the number of devices over which our array is sharded!
- The reason why the number of devices is still a problem in practice is because within a node, the weakest link is NVLink, where as going multi-node, the weakest link is InfiniBand
ReduceScatter
- A ReduceScatter sums an unreduced/partially summed array and then scatters (shards) a different logical axis along the same mesh axis
- The signature is:
\begin{align*} \textbf{ReduceScatter}_{Y,J} : A[I_X,J] \{U_Y\} \rightarrow &\ A[I_X, J_Y]\end{align*}
-
How does it work?
-
Assume a logical ring
-
Each starts with a tensor , which we’ll assume we will split into N equal-sized chunks:
- where means the j-th chunk of the tensor on
-
Let’s assume the one-directional algorithm for simplicity.
-
Each GPU will accumulate into its tensor the chunks of other neighbors.
-
There will be rounds, , the steps for
- Send chunk index to your right neighbor.
- Receive chunk index from your left neighbor.
- Accumulate (sum) the received chunk into your local buffer for that chunk
-
After rounds, each chunk has visited every GPU once and has been fully reduced.
-
Final ownership in the NCCL ring is a +1 rotation
- Indeed, the final chunk receives chunk index
- i.e. owns chunk
-
One more cyclic hop will have each GPU owning the correct chunk
-
-
How long does it take?
- Same runtime, as an all-gather, each GPU sends chunk of bytes times (one-directional) or 2 chunks of bytes times (bi-directional)
AllReduce
- An AllReduce takes an array with an unreduced (partially summed) axis and performs the sum by passing those shards around the unreduced axis and accumulating the result.
- The signature is:
-
This means it simply removes the suffix but otherwise leaves the result unchanged. ⇒ an all-reduce doesn’t change the sharding
-
AllReduce = reduceScatter + AllGather \begin{align*} \textbf{ReduceScatter}_{Y,J} : A[I_X,J] \{U_Y\} \rightarrow &\ A[I_X, J_Y] \\ \textbf{AllGather}_Y : A[I_X, J_Y] \rightarrow &\ A[I_X, J] \end{align*}
-
Thus, its runtime is 2 times the one of AllGather
AllToAll
-
Fundamental collective which does not occur naturally when considering sharded matrix multiplies
-
The AllToAll collective is a sharded transposition or resharding operation.
-
One example is if you want to shard along sequence length instead of channel-wise, when going from LayerNorm to context-parallel attention
-
This arises naturally when considering MoE models.
- you compute the gating ⇒ now we need to send and receive the corresponding shards for the expert present on the ranks.
- you move the sharding from sequence to EP
-
An AllToAll only has to pass shards part-way around the ring and is thus ¼ the cost of an AllGather